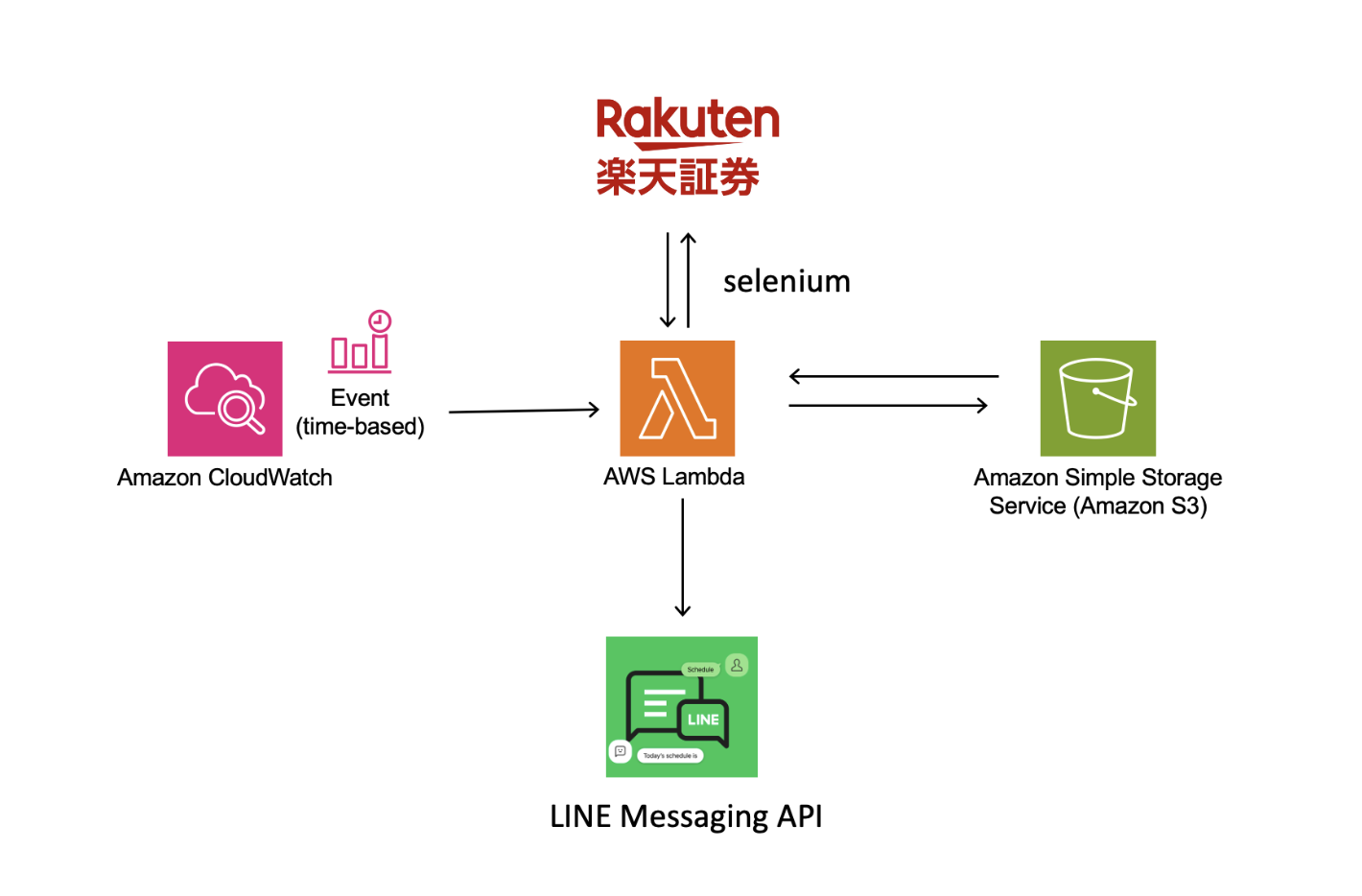
AWS Lambdaで楽天証券の評価損益・時価総額のスクショを送る(Python 3.11)
投稿日 6/28/2024
概要
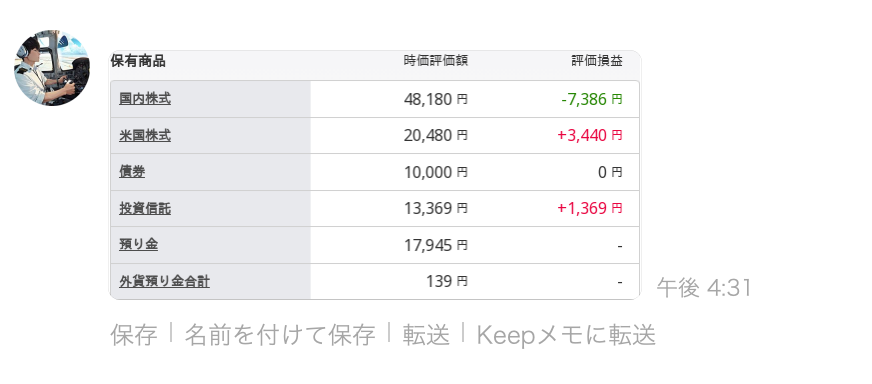
今回は、AWS Lambda を利用して楽天証券の Web ページから時価総額と評価損益のスクショを撮り、LINE で送信する方法を紹介します。
前提
-
環境
- MacBookAir(macOS 14.4, Apple Sillicon)
-
Docker 導入済み
-
AWS CLI のセットアップ済み
-
Python 3.12
修正済みのソースを見たい方はこちらから。
https://github.com/himawari-aerobytes/scraping-rakuten-sec/tree/main
ECR のイメージから Lambda 関数を作成
Selenium は Web ブラウザの操作を自動化するフレームワークです。https://qiita.com/Chanmoro/items/9a3c86bb465c1cce738a
今回は、Selenium を利用して Chrome を操作して楽天証券の画面のスクショを撮ります。
Selenium の利用には、Chrome のバイナリが必要になりますが、AWS Lambda では Chrome のバイナリがデフォルトでは使えません。Chrome のバイナリは 100MB 近くの容量が必要となります。しかし、zip ファイルでアップロードできる Lambda の容量は 250MB が上限です。Python の諸々のライブラリを含めると、容量制限に引っかかってしまいます。
250MB を超える場合は、ECR で docker イメージを利用して Lambda 関数を構築します。
ECR リポジトリの準備
まずは、AWS コンソールの ECR のページに飛びリポジトリの作成を押下します
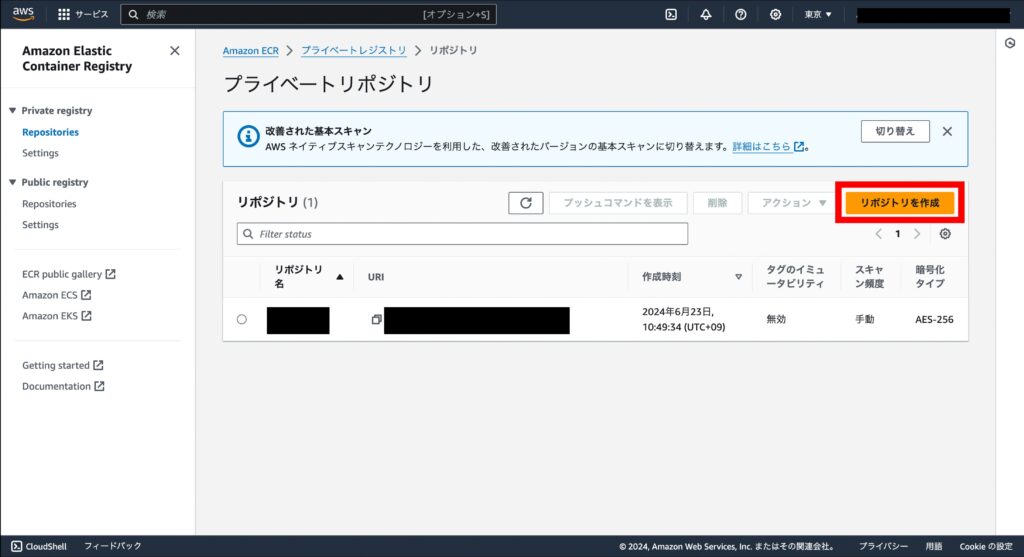
リポジトリ名に任意の名前(今回は selenium)を入力し「リポジトリを作成」を押下します
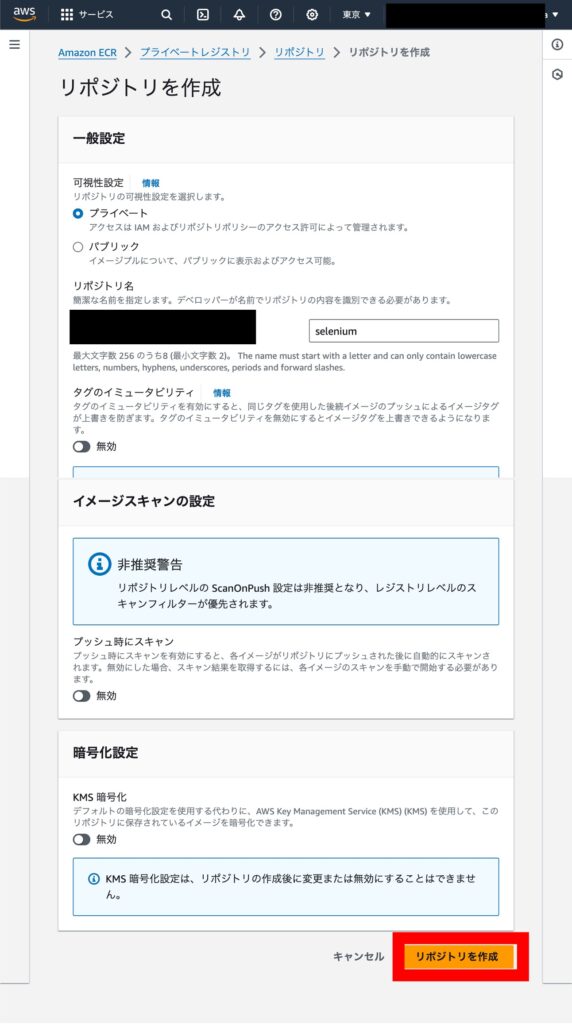
以下のような画面になれば成功です。ここで表示されている URI は以降使用するのでメモをしておいてください。
Docker イメージの push
この章では先程作成した ECR リポジトリに Docker イメージを push します。
Dockerfile の作成
Selenium や chromedriver などを導入したイメージを作成するために Dockerfile を作成します。
新規フォルダを作成し、Dockerfile を作成します。
開発環境が環境が Mac ではない場合、--platform=linux/amd64 の記述は削除してください。
Dockerfile
FROM --platform=linux/amd64 public.ecr.aws/lambda/python@sha256:fb31ca51357519a48a90f01a76e9d550778ecfcbe8d92dd832ec49b6672e387c as build
RUN dnf install -y unzip && \
curl -Lo "/tmp/chromedriver-linux64.zip" "https://edgedl.me.gvt1.com/edgedl/chrome/chrome-for-testing/119.0.6045.105/linux64/chromedriver-linux64.zip" && \
curl -Lo "/tmp/chrome-linux64.zip" "https://edgedl.me.gvt1.com/edgedl/chrome/chrome-for-testing/119.0.6045.105/linux64/chrome-linux64.zip" && \
unzip /tmp/chromedriver-linux64.zip -d /opt/ && \
unzip /tmp/chrome-linux64.zip -d /opt/
FROM --platform=linux/amd64 public.ecr.aws/lambda/python@sha256:fb31ca51357519a48a90f01a76e9d550778ecfcbe8d92dd832ec49b6672e387c
RUN dnf install -y atk cups-libs gtk3 libXcomposite alsa-lib \
libXcursor libXdamage libXext libXi libXrandr libXScrnSaver \
libXtst pango at-spi2-atk libXt xorg-x11-server-Xvfb \
xorg-x11-xauth dbus-glib dbus-glib-devel nss mesa-libgbm
RUN pip install selenium==4.15.2
RUN pip install python-dotenv
RUN pip install boto3
RUN pip install requests
RUN dnf -y install langpacks-ja
RUN dnf -y install ipa-gothic-fonts ipa-mincho-fonts ipa-pgothic-fonts ipa-pmincho-fonts
COPY --from=build /opt/chrome-linux64 /opt/chrome
COPY --from=build /opt/chromedriver-linux64 /opt/
COPY lambda/lambda_function.py ./
CMD [ "lambda_function.lambda_handler" ]
lambda_function.py の作成
Lambda で実行する関数を書きます。ファイル名は lambda_function.py と必ずしてください。
後述しますが、Lambda の環境変数として以下を設定しています。
| キー | 値 |
|---|---|
| BUCKET_NAME | 画像を保存する S3 バケット名 |
| ID | 楽天証券の ID |
| LINE_CHANNEL_ACCESS_TOKEN | LINE Messaging API のチャンネルアクセストークン |
| PASS | 楽天証券のパスワード |
| USER_ID | LINE のユーザ ID(送信先のユーザ ID) |
lambda_function.py
import os
from dotenv import load_dotenv
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.chrome.options import Options
import time
import datetime
import boto3
from botocore.exceptions import NoCredentialsError, PartialCredentialsError
import requests
import json
# 現在時刻の取得
def getNowTimeString():
# 時間の設定
t_delta = datetime.timedelta(hours=9)
JST = datetime.timezone(t_delta, 'JST')
now = datetime.datetime.now(JST)
return now.strftime("%Y%m%d%H%M%S")
def upload_to_s3(local_path, bucket_name, object_key):
s3_client = boto3.client('s3')
s3_client.upload_file(local_path, bucket_name, object_key)
return f"https://{bucket_name}.s3.amazonaws.com/{object_key}"
def generate_presigned_url(bucket_name, object_key, expiration=3600):
s3_client = boto3.client('s3')
try:
response = s3_client.generate_presigned_url('get_object',
Params={'Bucket': bucket_name,
'Key': object_key},
ExpiresIn=expiration)
except (NoCredentialsError, PartialCredentialsError) as e:
print("Credentials not available: ", e)
return None
return response
def send_LINE(now,local_path):
line_channel_access_token = os.environ.get("LINE_CHANNEL_ACCESS_TOKEN")
user_id = os.environ.get("USER_ID")
bucket_name = os.environ.get("BUCKET_NAME")
object_key = now+'_screenshot.png'
# 画像をS3にアップロードしてURLを取得
upload_to_s3(local_path, bucket_name, object_key)
uploaded_image_url = generate_presigned_url(bucket_name, object_key)
headers = {
"Content-Type": "application/json",
"Authorization": f"Bearer {line_channel_access_token}"
}
data = {
"to": user_id,
"messages": [
{
"type": "image",
"originalContentUrl": uploaded_image_url,
"previewImageUrl": uploaded_image_url
}
]
}
response = requests.post(
"https://api.line.me/v2/bot/message/push",
headers=headers,
data=json.dumps(data)
)
return {
'statusCode': response.status_code,
'body': response.text
}
def lambda_handler(event,context):
load_dotenv()
# Optionの設定
chrome_options = Options()
chrome_options.add_argument("--headless")
chrome_options.add_argument("--no-sandbox")
chrome_options.add_argument("--disable-dev-shm-usage")
chrome_options.add_argument("--single-process")
chrome_options.add_argument("--disable-gpu")
chrome_options.add_argument("--window-size=1280x1696")
chrome_options.add_argument("--user-data-dir=/tmp/user-data")
chrome_options.add_argument("--data-path=/tmp/data-path")
chrome_options.add_argument("--disk-cache-dir=/tmp/cache-dir")
chrome_options.add_argument("--homedir=/tmp")
chrome_options.binary_location = "/opt/chrome/chrome"
driver = webdriver.Chrome(options=chrome_options, service=Service("/opt/chromedriver"))
driver.get('https://www.rakuten-sec.co.jp/ITS/V_ACT_Login.html') #特定のURLへ移動
time.sleep(1)
# ログイン処理
loginId = driver.find_element(By.NAME, 'loginid')
password = driver.find_element(By.NAME, 'passwd')
loginId.clear()
password.clear()
loginId.send_keys(os.environ.get("ID"))
password.send_keys(os.environ.get("PASS"))
loginId.submit()
time.sleep(5)
allBreakdown=driver.find_element(By.ID,'homeAssetsTrigger')
allBreakdown.click()
time.sleep(5)
portfolio = driver.find_element(By.ID, 'balance_data_actual_data')
# 画面最大化
driver.maximize_window()
now = getNowTimeString()
time.sleep(5)
print(portfolio.location)
local_path= '/tmp/'+now+'_screenshot.png'
portfolio.screenshot(local_path)
driver.quit()
# LINE送信処理
return send_LINE(now,local_path)
Docker イメージの作成
Dockerfile と lamda_function.py を作成したフォルダ内で以下のコマンドを実行します。
$ docker build -t selenium .
イメージを push するために、タグをつけます。(URI は AWS ECR リポジトリ一覧に表示されていた URI に置き換えてください。)
$ docker tag selenium:latest 123456789012.dkr.ecr.ap-northeast-1.amazonaws.com/selenium:latest
ECR にログインするために、以下のコマンドを実行します(URI は AWS ECR リポジトリ一覧に表示されていた URI に置き換えてください。)
$ aws ecr get-login-password | docker login --username AWS --password-stdin 123456789012.dkr.ecr.ap-northeast-1.amazonaws.com
イメージを ECR に push するために以下のコマンドを実行します。(URI は Amazon ECR リポジトリ一覧に表示されていた URI に置き換えてください。)
$ docker push 123456789012.dkr.ecr.ap-northeast-1.amazonaws.com/selenium:latest
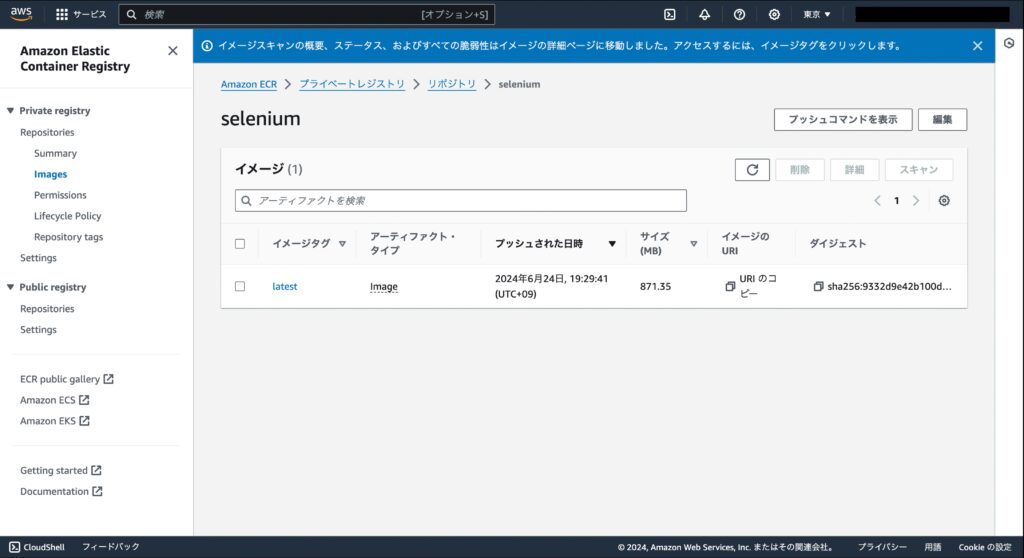
push が完了すると、ECR リポジトリ内に latest タグの付いたイメージが追加されていることが確認できます。
Lambda 関数の作成
AWS コンソールの Lambda のページに飛びます。左上の「関数の作成」を押下します
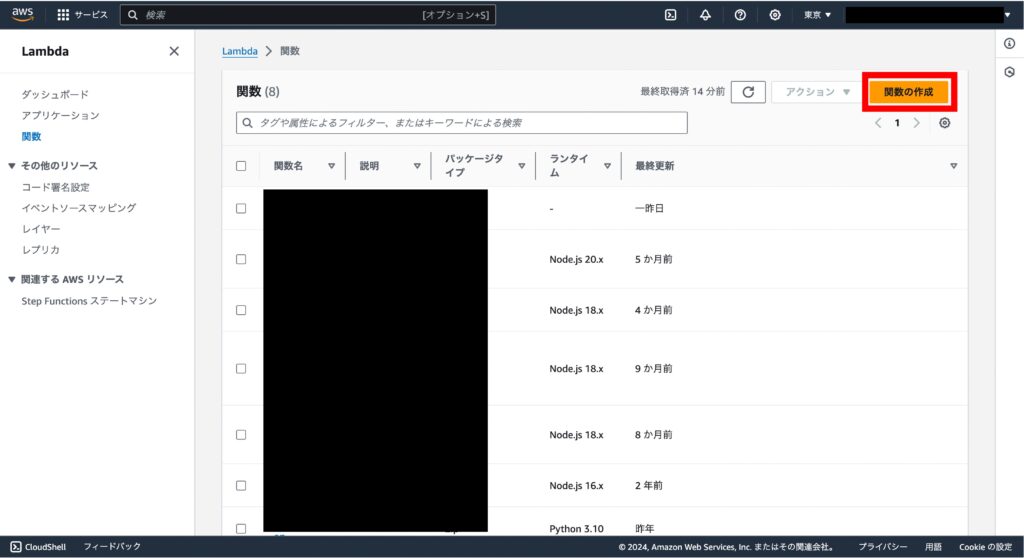
「コンテナイメージ」を選択します。
「イメージの作成」から先ほど作成した ECR の URI をペーストします。
その後、Lambda から S3 にアップロードする権限を付与するために、IAM コンソールから IAM ロールを作成します。
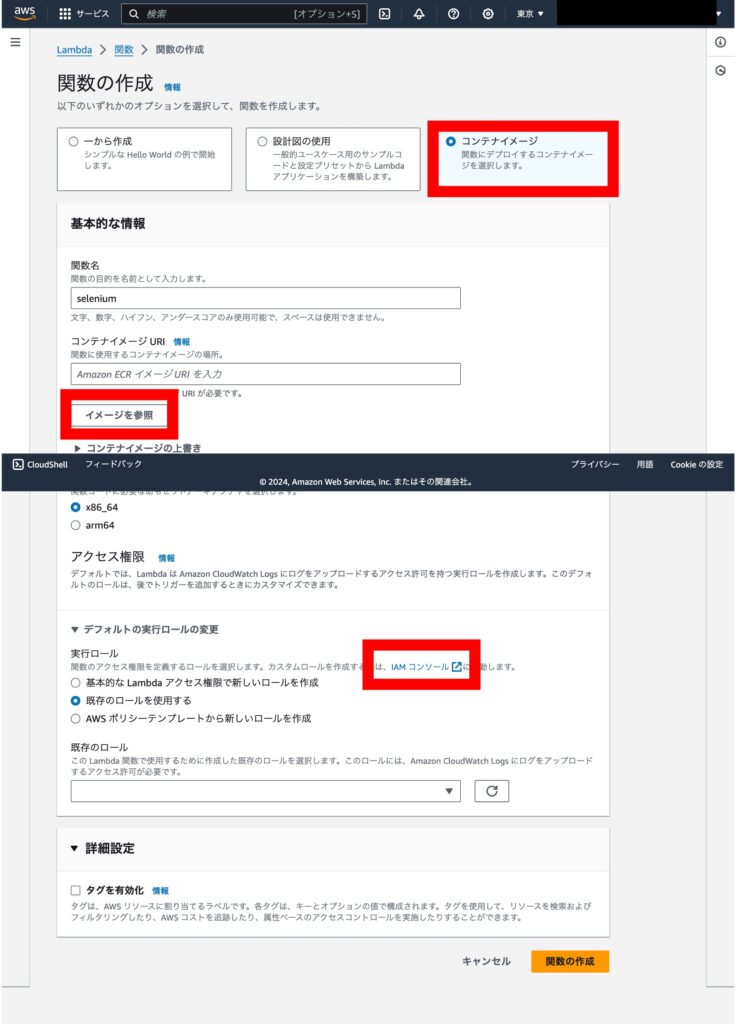
「サービスまたはユースケース」で、「Lambda」し、「次へ」を選択します。
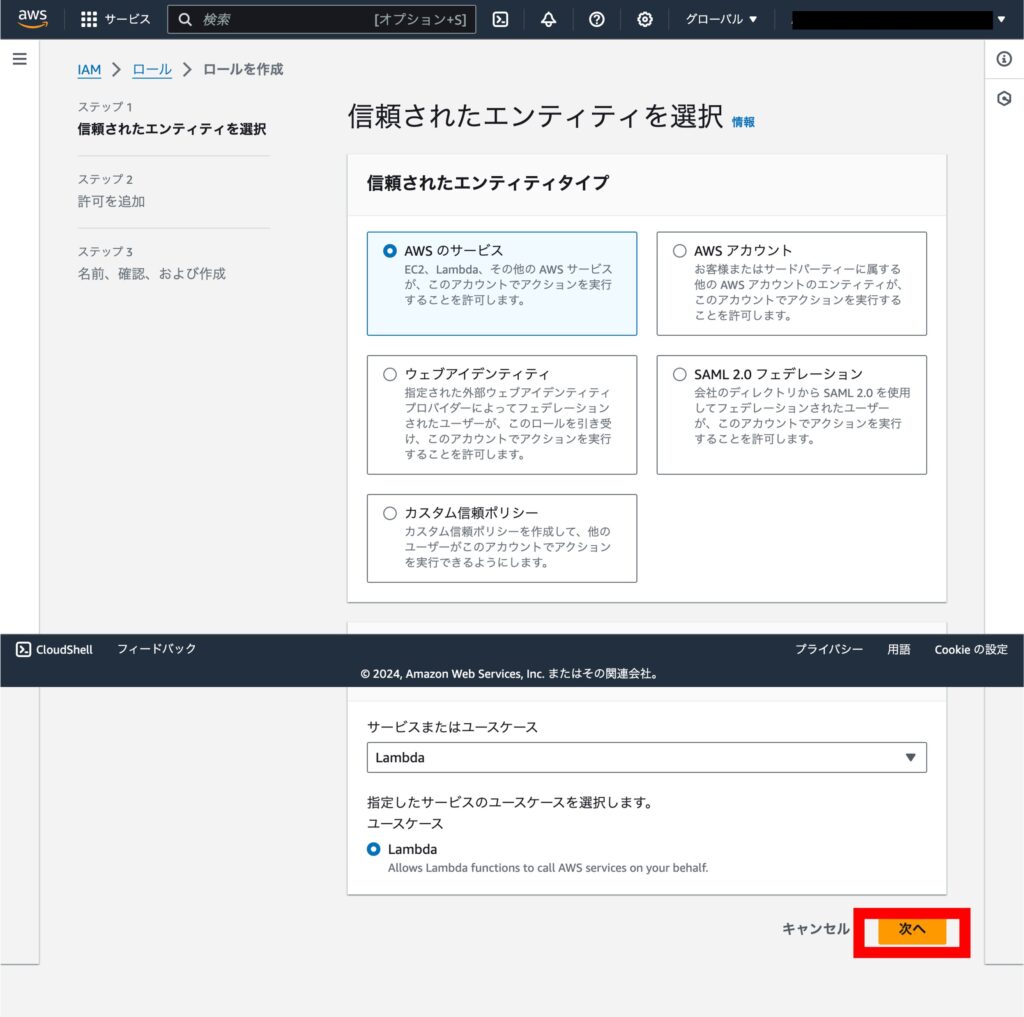
「AmazonS3FullAccess」を許可ポリシーに追加し、「次へ」を選択します。
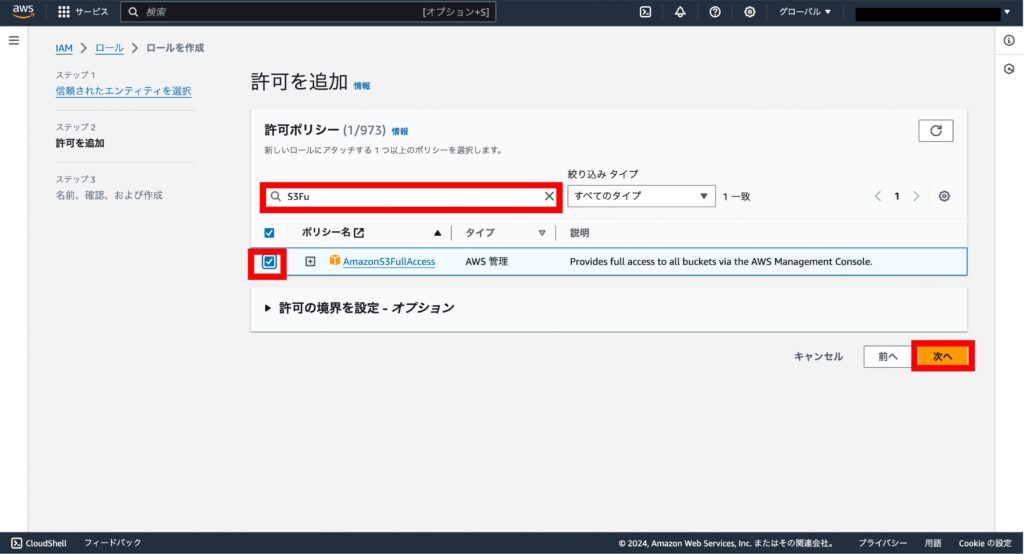
ロール名に、role-selenium-lambda(任意の名前)を入力し、「ロールの作成」を押下します。
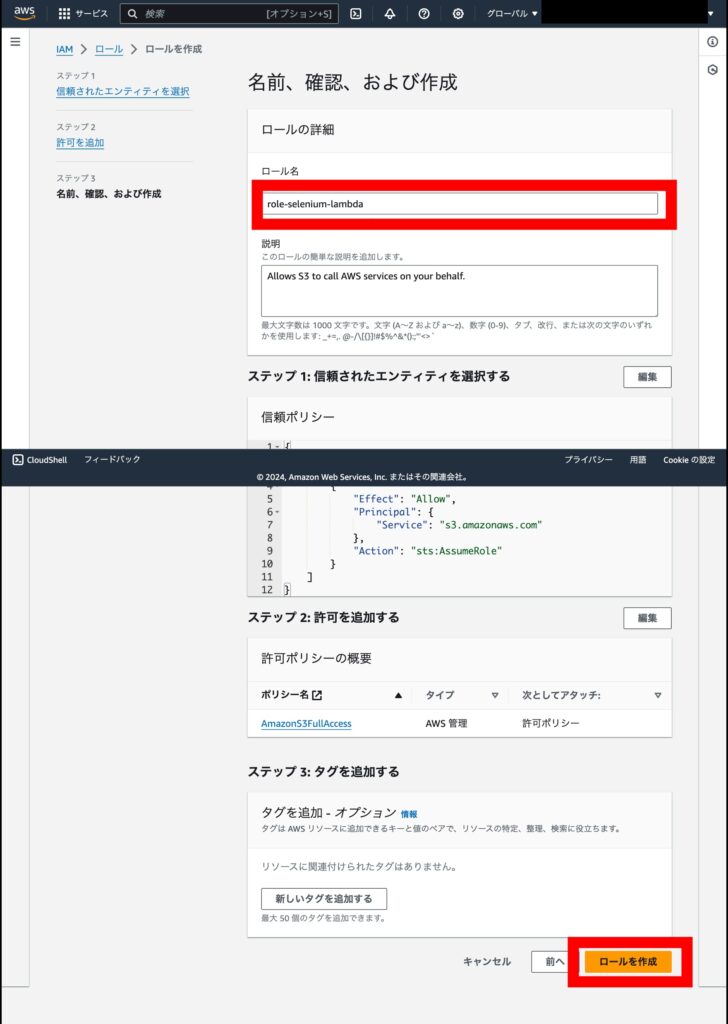
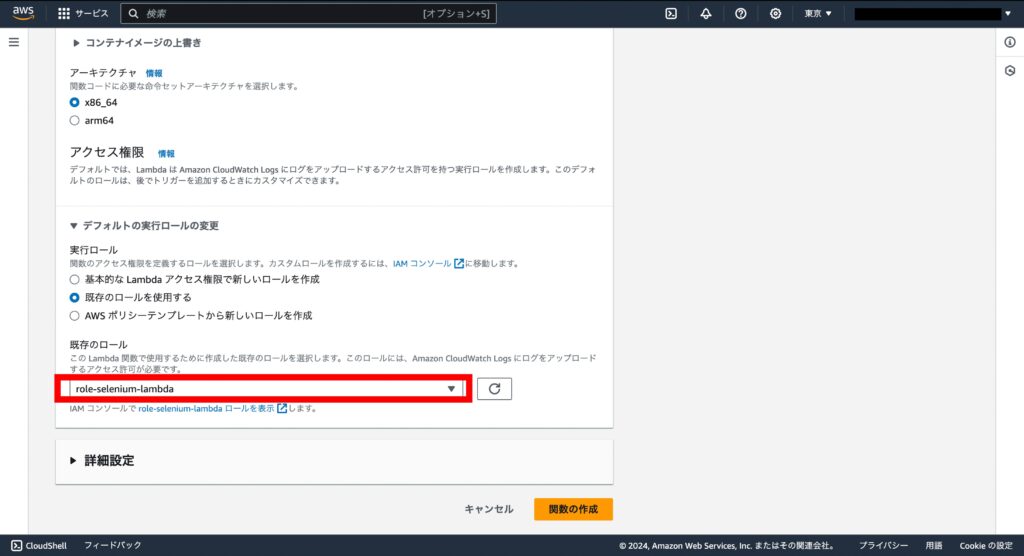
Lambda のページに戻り、「既存のロール」に先ほど作成したロールを設定し、「関数の作成」を押下します。
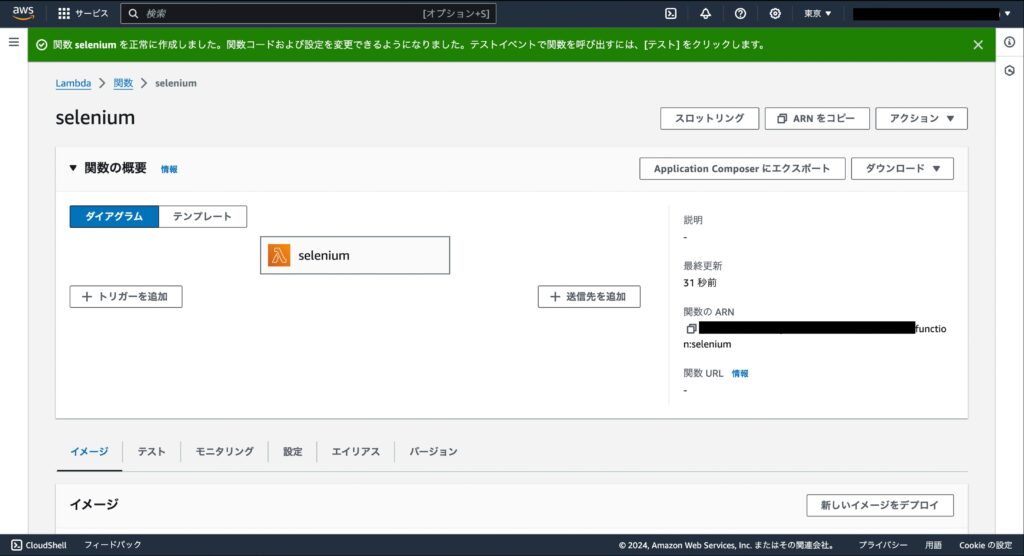
関数の作成が完了すると「正常に作成しました」と表示されます。
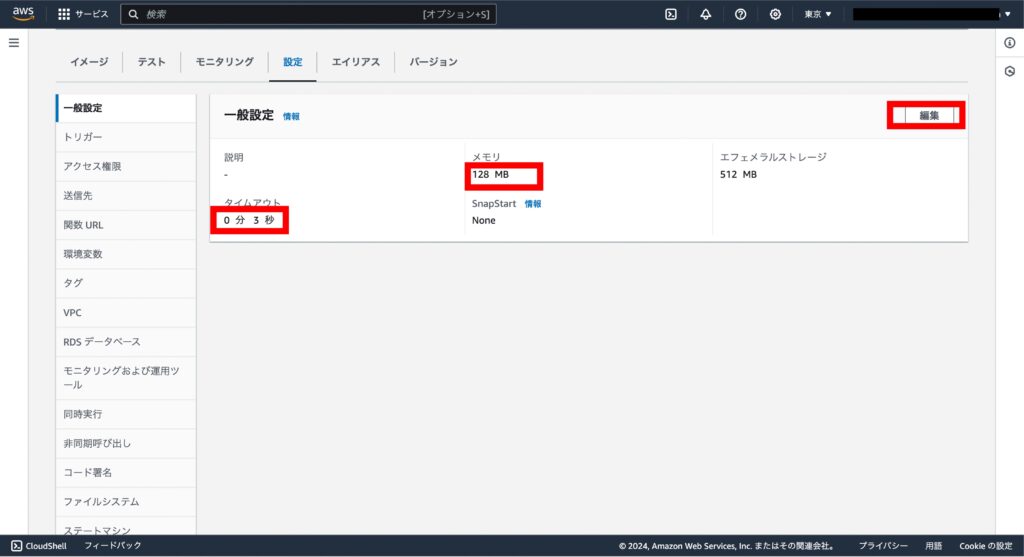
設定タブから「メモリ」を 512MB、「タイムアウト」を 2 分 0 秒に設定します
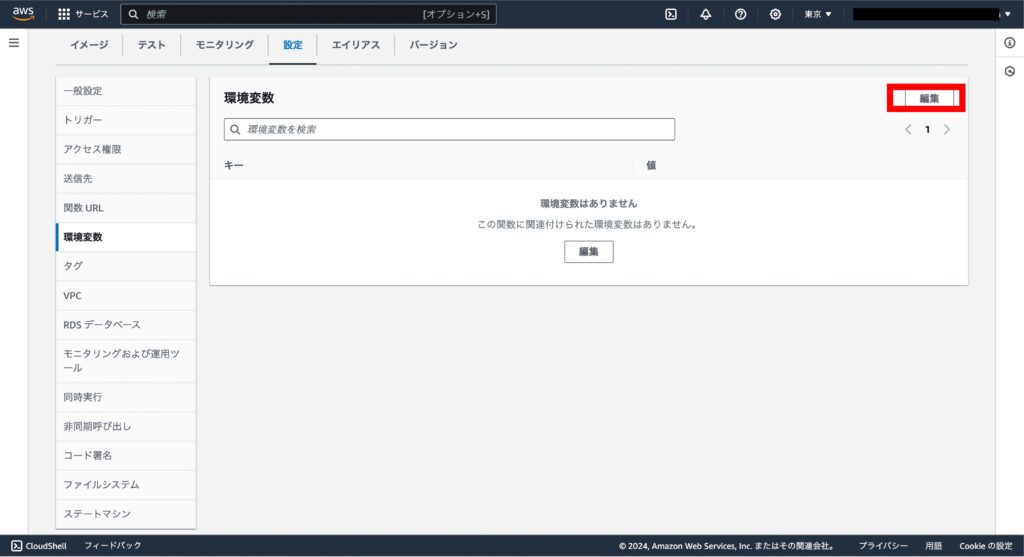
環境変数に以下を設定します。
| キー | 値 |
|---|---|
| BUCKET_NAME | 画像を保存する S3 バケット名 |
| ID | 楽天証券の ID |
| LINE_CHANNEL_ACCESS_TOKEN | LINE Messaging API のチャンネルアクセストークン |
| PASS | 楽天証券のパスワード |
| USER_ID | LINE のユーザ ID(送信先のユーザ ID) |
LINE Messaging API と S3 バケット名の取得
LINE Developers のページに行きます。https://developers.line.biz/console/
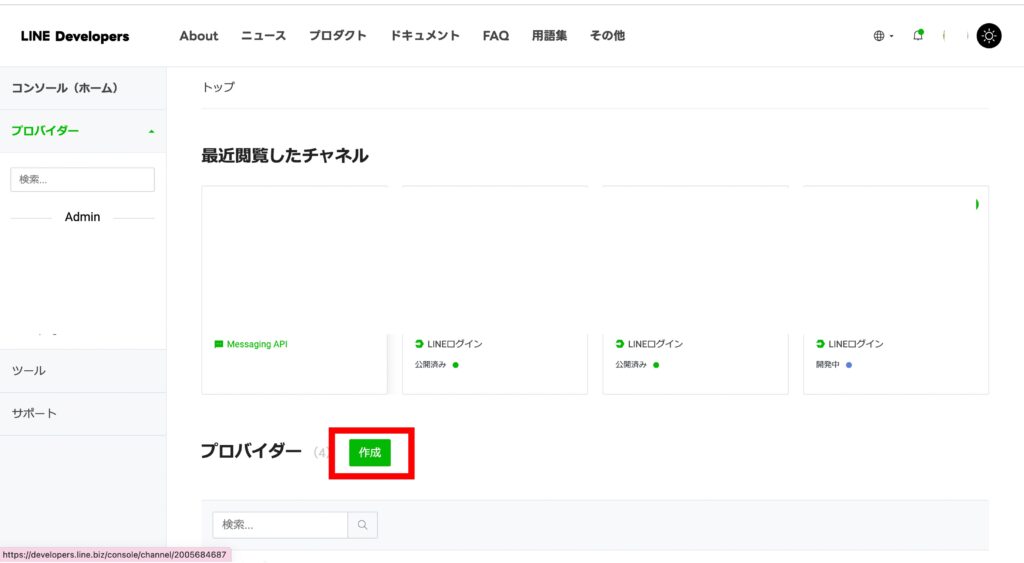
「プロバイダー」から「作成」を選択します
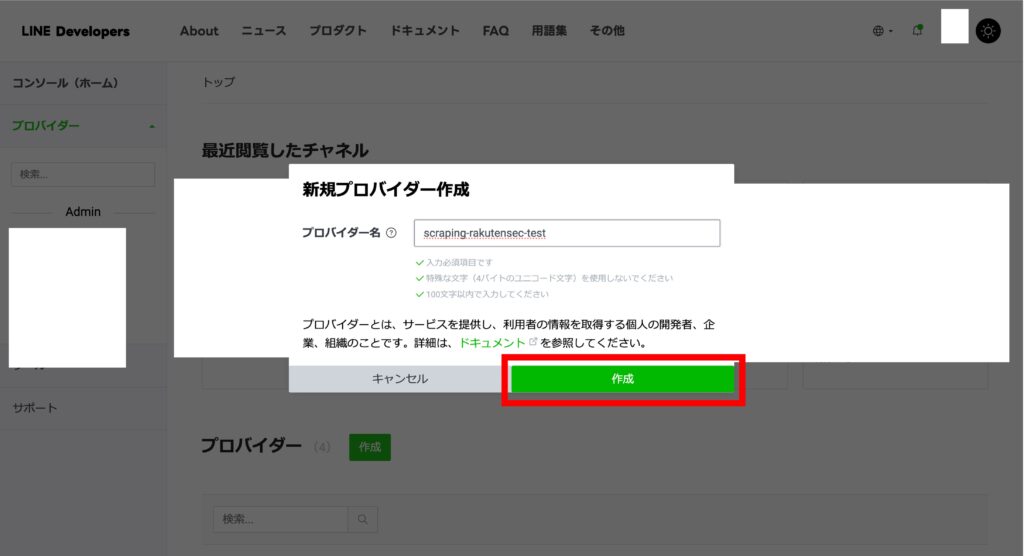
「プロバイダー名」に scraping-rakutensec-test(任意の名前)を入力します。
「作成」を押下します
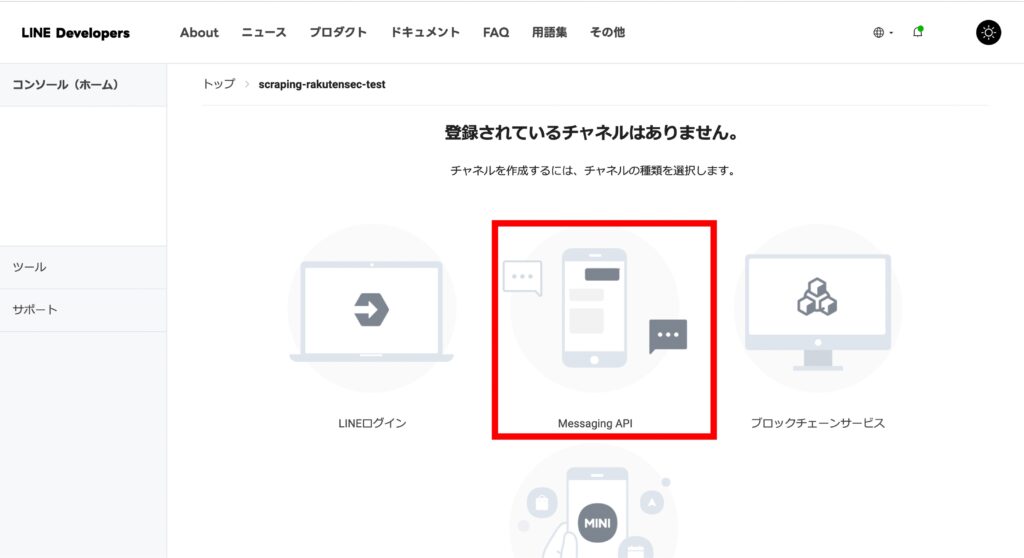
「Messaging API」を選択します。
チャネル名、チャネル説明、大業種、小業種、メールアドレスを入力します。
「作成」を押下します。
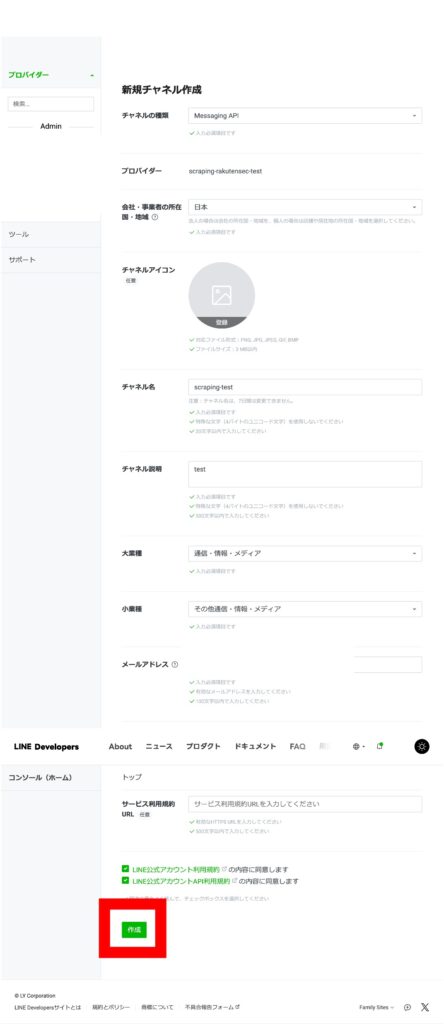
「チャネルシークレット(環境変数の LINE_CHANNEL_ACCESS_TOKEN)」「あなたのユーザ ID(環境変数の USER_ID)」を確認し、Lambda の環境変数に登録します。
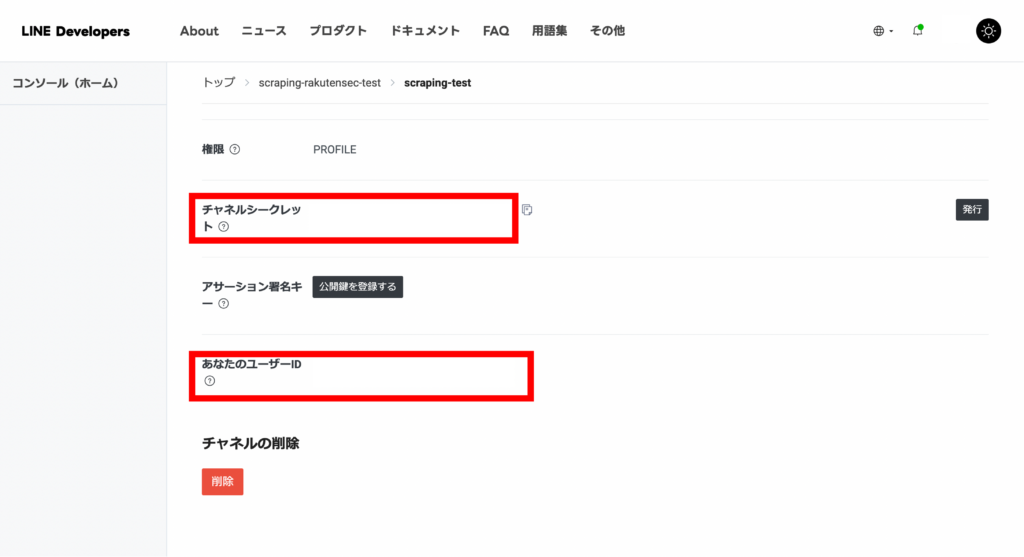
「Messaging API 設定」のタブから「QR コード」を読み取り、LINE Bot を友だち登録します。
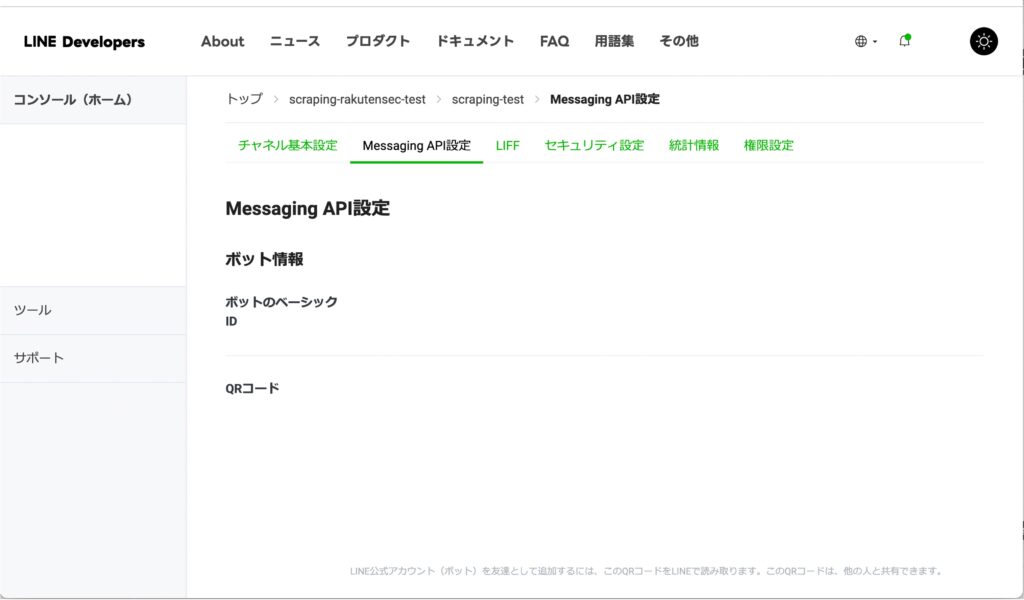
AWS コンソールから、S3 のページに飛びます。
「バケットを作成」を押下します。
「バケット名」に、名前を入力します。こちらが環境変数 BUCKET_NAME になります。Lambda の環境変数にこちらも登録します。
「バケットを作成」を押下します。
以上で、手順は完了です。
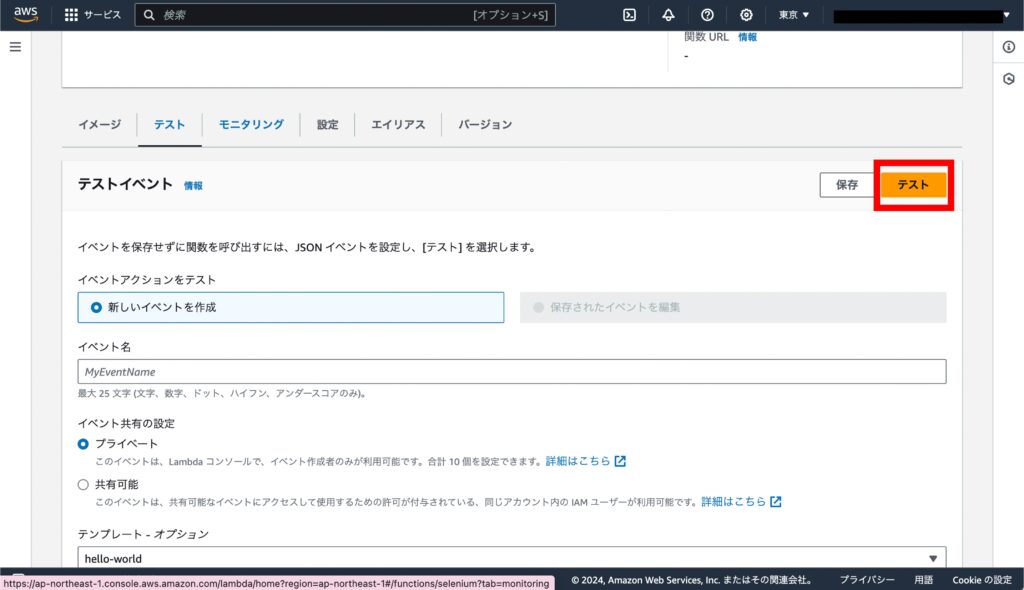
Lambda でテストを実行
Lambda で Selenium のページに行き、「テスト」を実行すると LINE で画像が送られてきます。